WARNING: The information on this is outdated. We recommend looking into the up-to-date documentation at trac (internal) and ReadTheDocs.
Read this post first if your development environment needs setting up. Then…
Setting Up the Database
To install the database, open a Terminal session and do:
pip install BDNYCdb
Then download the public database file BDNCY198.db here or get the unpublished BDNYC.db file from Dropbox. (Ask a group member for the invite!)
Accessing the Database
Now you can load the entire database into a Python variable simply by launching the Python interpreter and pointing the get_db() function to the database file by doing:
In [1]: from BDNYCdb import BDdb
In [2]: db = BDdb.get_db('/path/to/your/Dropbox/BDNYCdb/BDNYC.db')
Voila!
In the database, each source has a unique identifier (or ‘primary key’ in SQL speak). To see an inventory of all data for one of these sources, just do:
In [3]: db.inventory(id)
where id is the source_id.
Now that you have the database at your fingertips, you’ll want to get some info out of it. To do this, you can use SQL queries.
Here is a detailed post about how to write an SQL query.
Further documentation for sqlite3 can be found here. Most commands involve wrapping SQL language inside python functions. The main method we will use to fetch data from the database is list():
In [5]: data = db.list( "SQL_query_goes_here" ).fetchall()
Example Queries
Some SQL query examples to put in the command above (wrapped in quotes of course):
- SELECT shortname, ra, dec FROM sources WHERE (222<ra AND ra<232) AND (5<dec AND dec<15)
- SELECT band, magnitude, magnitude_unc FROM photometry WHERE source_id=58
- SELECT source_id, band, magnitude FROM photometry WHERE band=’z’ AND magnitude<15
- SELECT wavelength, flux, unc FROM spectra WHERE observation_id=75”
As you hopefully gathered:
- Returns the shortname, ra and dec of all objects in a 10 square degree patch of sky centered at RA = 227, DEC = 10
- Returns all the photometry and uncertainties available for object 58
- Returns all objects and z magnitudes with z less than 15
- Returns the wavelength, flux and uncertainty arrays for all spectra of object 75
The above examples are for querying individual tables only. We can query from multiple tables at the same time with the JOIN command like so:
- SELECT t.name, p.band, p.magnitude, p.magnitude_unc FROM telescopes as t JOIN photometry AS p ON p.telescope_id=t.id WHERE p.source_id=58
- SELECT p1.magnitude-p2.magnitude FROM photometry AS p1 JOIN photometry AS p2 ON p1.source_id=p2.source_id WHERE p1.band=’J’ AND p2.band=’H’
- SELECT src.designation, src.unum, spt.spectral_type FROM sources AS src JOIN spectral_types AS spt ON spt.source_id=src.id WHERE spt.spectral_type>=10 AND spt.spectral_type<20 AND spt.regime=’optical’
- SELECT s.unum, p.parallax, p.parallax_unc, p.publication_id FROM sources as s JOIN parallaxes AS p ON p.source_id=s.id
As you may have gathered:
- Returns the survey, band and magnitude for all photometry of source 58
- Returns the J-H color for every object
- Returns the designation, U-number and optical spectral type for all L dwarfs
- Returns the parallax measurements and publications for all sources
Alternative Output
As shown above, the result of a SQL query is typically a list of tuples where we can use the indices to print the values. For example, this source’s g-band magnitude:
In [9]: data = db.list("SELECT band,magnitude FROM photometry WHERE source_id=58").fetchall()
In [10]: data
Out[10]: [('u', 25.70623),('g', 25.54734),('r', 23.514),('i', 21.20863),('z', 18.0104)]
In [11]: data[1][1]
Out[11]: 25.54734
However we can also query the database a little bit differently so that the fields and records are returned as a dictionary. Instead of db.query.execute() we can do db.dict() like this:
In [12]: data = db.dict("SELECT * FROM photometry WHERE source_id=58").fetchall()
In [13]: data
Out[13]: [<sqlite3.Row at 0x107798450>, <sqlite3.Row at 0x107798410>, <sqlite3.Row at 0x107798430>, <sqlite3.Row at 0x1077983d0>, <sqlite3.Row at 0x1077982f0>]
In [14]: data[1]['magnitude']
Out[14]: 25.54734
Database Schema and Browsing
In order to write the SQL queries above you of course need to know what the names of the tables and fields in the database are. One way to do this is:
In [15]: db.list("SELECT sql FROM sqlite_master").fetchall()
This will print a list of each table, the possible fields, and the data type (e.g. TEXT, INTEGER, ARRAY) for that field.
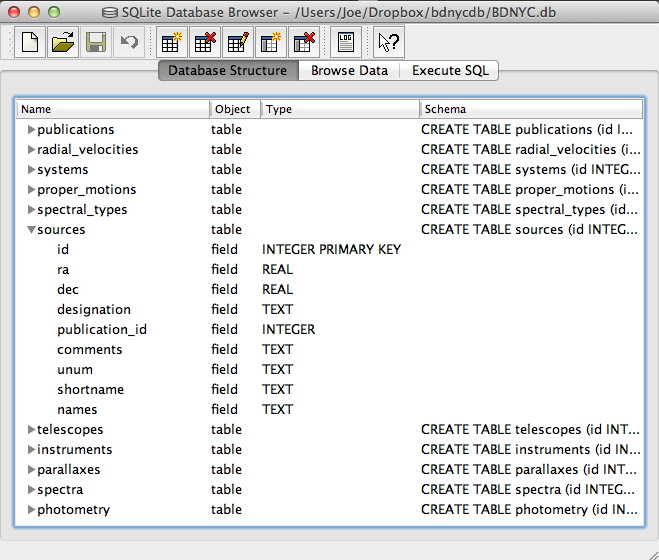 Even easier is to use the DB Browser for SQLite pictured at left which lets you expand and collapse each table, sort and order columns, and other fun stuff.
Even easier is to use the DB Browser for SQLite pictured at left which lets you expand and collapse each table, sort and order columns, and other fun stuff.
It even allows you to manually create/edit/destroy records with a very nice GUI.
IMPORTANT: If you are using the private database keep in mind that if you change a database record, you immediately change it for everyone since we share the same database file on Dropbox. Be careful!
Always check and double-check that you are entering the correct data for the correct source before you save any changes with the SQLite Database Browser.