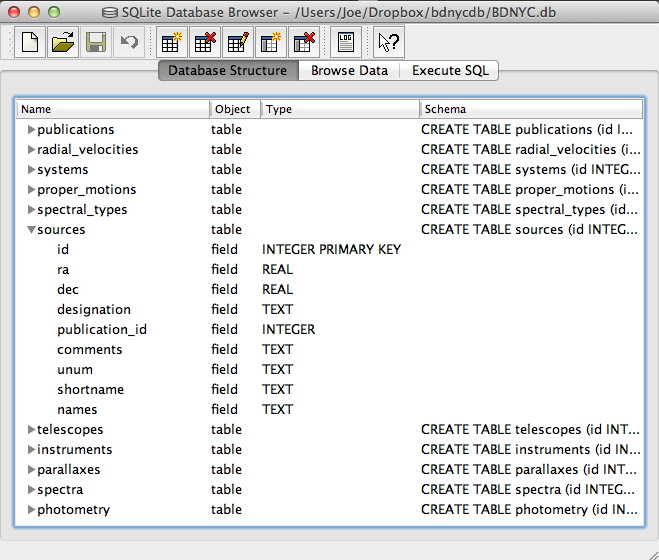
An SQL database is comprised of a bunch of tables (kind of like a spreadsheet) that have fields (column names) and records (rows of data). For example, our database might have a table called students that looks like this:
| id |
first |
last |
grade |
GPA |
| 1 |
Al |
Einstein |
6 |
2.7 |
| 2 |
Annie |
Cannon |
6 |
3.8 |
| 3 |
Artie |
Eddington |
8 |
3.2 |
| 4 |
Carlie |
Herschel |
8 |
3.2 |
So in our students table, the fields are [id, first, last, grade, GPA], and there are a total of four records, each with a required yet arbitrary id in the first column.
To pull these records out, we tell SQL to SELECT values for the following fields FROM a certain table. In SQL this looks like:
In [1]: db.execute("SELECT id, first, last, grade, GPA FROM students").fetchall()
Out[1]: [(1,'Al','Einstein',6,2.7),(2,'Annie','Cannon',6,3.8),(3,'Artie','Eddington',8,3.2),(4,'Carlie','Herschel',8,3.2)]
Or equivalently, we can just use a wildcard “*” if we want to return all fields with the SQL query "SELECT * FROM students".
We can modify our SQL query to change the order of fields or only return certain ones as well. For example:
In [2]: db.execute("SELECT last, first, GPA FROM students").fetchall()
Out[1]: [('Einstein','Al',2.7),('Cannon','Annie',3.8),('Eddington','Artie',3.2),('Herschel','Carlie',3.2)]
Now that we know how to get records from tables, we can restrict which records it returns with the WHERE statement:
In [3]: db.execute("SELECT last, first, GPA FROM students WHERE GPA>3.1").fetchall()
Out[3]: [('Cannon','Annie',3.8),('Eddington','Artie',3.2),('Herschel','Carlie',3.2)]
Notice the first student had a GPA less than 3.1 so he was omitted from the result.
Now let’s say we have a second table called quizzes which is a table of every quiz grade for all students that looks like this:
| id |
student_id |
quiz_number |
score |
| 1 |
1 |
3 |
89 |
| 2 |
2 |
3 |
96 |
| 3 |
3 |
3 |
94 |
| 4 |
4 |
3 |
92 |
| 5 |
1 |
4 |
78 |
| 6 |
3 |
4 |
88 |
| 7 |
4 |
4 |
91 |
Now if we want to see only Al’s grades, we have to JOIN the tables ON some condition. In this case, we want to tell SQL that the student_id (not the id) in the quizzes table should match the id in the students table (since only those grades are Al’s). This looks like:
In [4]: db.execute("SELECT quizzes.quiz_number, quizzes.score FROM quizzes JOIN students ON students.id=quizzes.student_id WHERE students.last='Einstein'").fetchall()
Out[4]: [(3,89),(4,78)]
So students.id=quizzes.student_id associates each quiz with a student from the students table and students.last='Einstein' specifies that we only want the grades from the student with last name Einstein.
Similarly, we can see who scored 90 or greater on which quiz with:
In [5]: db.execute("SELECT students.last, quizzes.quiz_number, quizzes.score FROM quizzes JOIN students ON students.id=quizzes.student_id WHERE quizzes.score>=90").fetchall()
Out[5]: [('Cannon',3,96),('Eddington',3,94),('Herschel',3,92),('Herschel',4,91)]
That’s it! We can JOIN as many tables as we want with as many restrictions we need to pull out data in the desired form.
This is powerful, but the queries can become lengthy. A slight shortcut is to use the AS statement to assign a table to a variable (e.g. students => s, quizzes => q) like such:
In [6]: db.execute("SELECT s.last, q.quiz_number, q.score FROM quizzes AS q JOIN students AS s ON s.id=q.student_id WHERE q.score>=90").fetchall()
Out[6]: [('Cannon',3,96),('Eddington',3,94),('Herschel',3,92),('Herschel',4,91)]